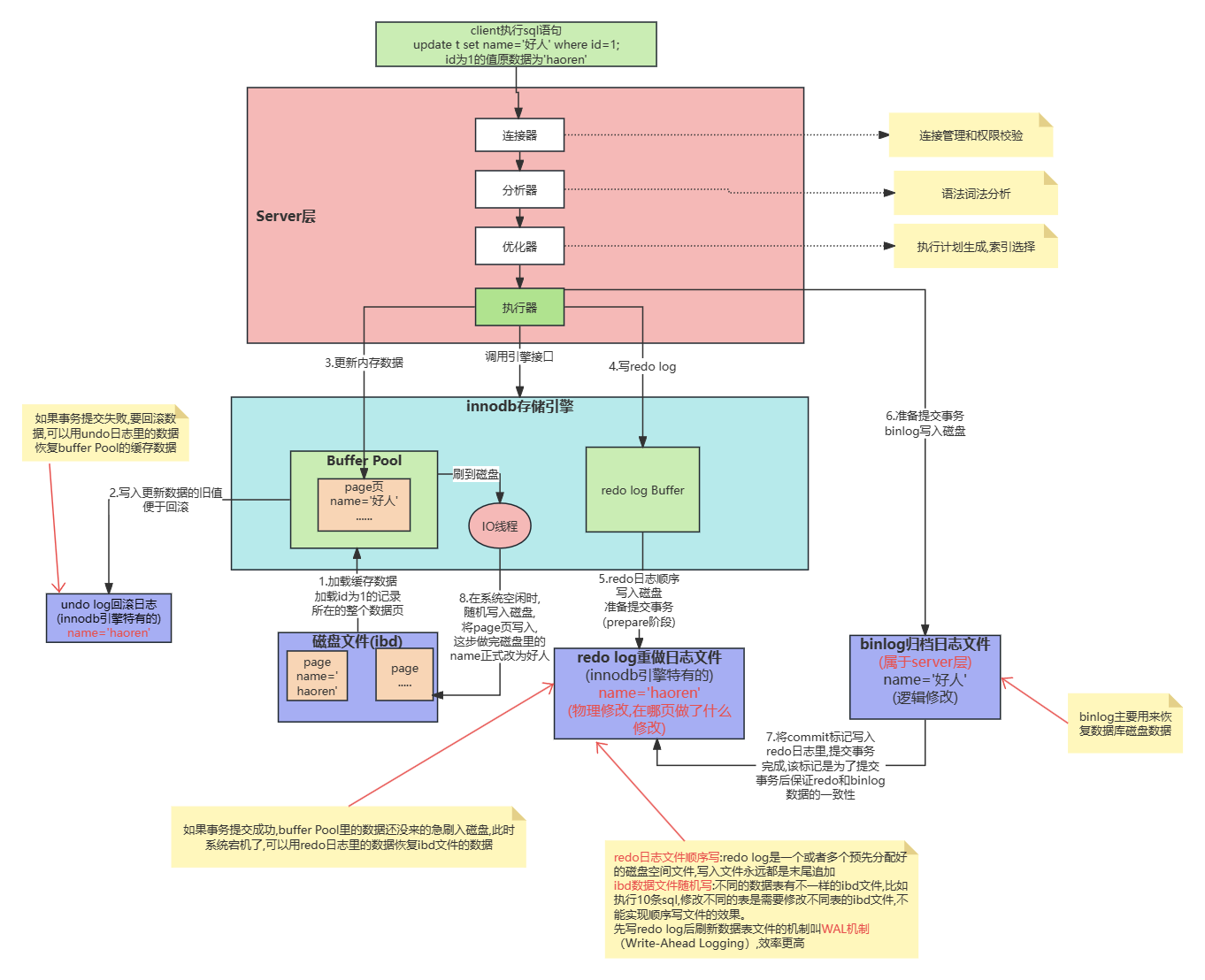
资源分配
线程束的本地执行上下文主要由以下资源组成:
- 程序计数器
- 寄存器
- 共享内存
由SM处理的每个线程束的执行上下文,在整个线程束的生存期中是保存在芯片内的。
SM的关键组件:
- CUDA核心
- 共享内存/一级缓存
- 寄存器文件
- 加载/存储单元
- 特殊功能单元
- 线程束调度器
每个SM都有32位的寄存器组,存储在寄存器文件中,在线程中进行分配。
SM(Streaming Multiprocessor,流多处理器)寄存器是指用于存储线程的状态和临时数据的存储器单元。每个线程在执行时都会被分配一定数量的寄存器,用于存储其局部变量、中间计算结果等。这些寄存器是线程私有的,不同线程之间不能直接访问对方的寄存器。
SM寄存器的作用包括但不限于以下几点:
存储线程状态:每个线程在执行时需要保存一些状态信息,如程序计数器、栈指针等,这些状态信息存储在寄存器中。
存储局部变量:线程执行过程中使用的局部变量和临时变量都存储在寄存器中。由于寄存器的读写速度非常快,因此可以提高程序的执行效率。
存储中间计算结果:在执行复杂计算过程中,线程可能需要存储一些中间计算结果,这些结果也存储在寄存器中,以便后续使用。
存储函数调用相关信息:如果线程调用了函数,那么函数调用相关的信息,如参数、返回地址等也会存储在寄存器中。
每个线程消耗的寄存器越多,一个SM上可以处理的线程束越少;每个线程块使用的共享内存越多,一个SM上可以处理的线程块越少。
资源可用性会限制SM中常驻线程块的数量,如果每个SM中没有足够的寄存器或共享内存处理至少一个线程块,那么内核将无法启动。
一旦计算资源被分配给线程块,该线程块被称为活跃的块。它所包含的线程束被称为活跃的线程束。活跃的线程束可以被细分为以下三种:
- 选定的线程束
- 阻塞的线程束
- 符合条件的线程束
一个SM上的线程束调度器在每个周期都选择活跃的线程束,然后将它们调度到执行单元。活跃执行的线程束被称为选定的线程束。如果一个活跃的线程束准备执行但尚未执行,则是一个符合条件的线程束,没有做好准备的线程束是阻塞的线程束。
计算资源限制了活跃的线程束的数量。因此必须了解由硬件产生的限制和内核用到的资源。为了最大程度的利用GPU,需要最大化活跃的线程束数量。
延迟隐藏
SM在指令发出和完成之间的时钟周期被定义为指令延迟。当每个时钟周期中所有的线程调度器都有一个符合条件的线程时,可以达到计算资源的完全利用。
考虑到指令迟延,GPU的指令和对应的延迟可以被分为两种类型:
- 算数指令 10~20个周期
- 内存指令 400~800个周期
如何估算隐藏延迟所需要的活跃线程束数量,使用利特尔法则。
所需线程束数量 = 延迟 * 吞吐量
带宽与吞吐量:带宽指理论峰值,吞吐量指已到达的值。
所谓延迟隐藏,其实不是将延迟“消失”,而是在大规模的并行中,在某个或某些线程发生延迟时,比如在某个线程读取内存时,在这段计算周期中进行其他可行的线程计算或其他处理。将线程的延迟“隐藏”起来。
同步
CUDA中,同步可以在两个不同的级别执行:
- 系统级:等待主机或设备完成所有工作
- 块级:在设备执行过程中,等待一个线程块中的所有线程到达同一点。
对于主机来说,许多CUDA API调用和所有的内核启动不是同步的,以下这个函数可以用来阻塞主机程序,直到完成所有的CUDA操作
cudaError_t cudaDeviceSynchronize(void);这个函数可能会从先前的先前的CUDA异步操作返回错误。
GPT的解释:
cudaDeviceSynchronize函数可能从先前的异步CUDA操作返回错误的原因通常与异步操作的执行有关。在CUDA编程中,很多操作都可以以异步方式执行,例如内存拷贝、核函数启动等。当使用异步操作时,操作并不会立即执行,而是会在后台等待GPU资源可用时才会执行。如果在调用
cudaDeviceSynchronize之前有未完成的异步操作,那么这些操作可能会在cudaDeviceSynchronize中执行时引发错误。例如,如果在调用cudaMemcpyAsync拷贝数据之后立即调用cudaDeviceSynchronize,但数据拷贝操作尚未完成,那么cudaDeviceSynchronize可能会返回错误,因为它等待的操作尚未完成。
因为在一个线程块中的线程束以一个未定义的顺序执行,CUDA提供了一个使用块局部栅栏来同步它们的执行的功能。
__device__ void __syncthreads(void);在该函数被调用时,在同一个线程块中的所有线程都必须等待直至线程块中的所有其他线程都到达这个同步点。
在不同的块之间没有线程同步。块间同步,唯一安全的方法是在每个内核执行结束端使用全局同步点;也就是说,在全局同步后,终止当前的核函数,开始执行新的核函数。